
the cost of AI reasoning is going to drastically decrease
As time progresses, AI models are achieving higher reasoning accuracy while their associated costs continue to drastically decrease. What does it mean for our future?

Over the years language models (LMs) have demonstrated remarkable reasoning capabilities across diverse tasks, as measured by the commonly used Massive Multitask Language Understanding (MMLU) benchmark. Simultaneously, the cost of running these models has significantly decreased due to innovations such as Mixture of Experts (MoE), compute and parameter-efficient training and inference techniques, hardware/chip advancements, etc. These developments have enabled LLMs to achieve impressive performance while reducing computational requirements and operational costs.
An interesting question to ask is what’s the trend of AI reasoning costs over time. So, I made a plot, showcasing the performance of language models on the MMLU benchmark against their cost, spanning from 2022 to the present day. The resulting visualization has a clear trend: as time progresses, language models are achieving higher MMLU accuracy scores while their associated costs continue to drastically decrease.

It is quite fascinating that models are reaching around 80% MMLU accuracy at costs orders of magnitude lower than just a couple of years prior. Even within the same model family, newer versions tend to be both more capable and more efficient. For example, Claude 3 Sonnet outperforms Claude 2 in accuracy while being more affordable. To provide a comprehensive overview, I have compiled the data in a spreadsheet, which includes links to price and accuracy scores for each model, as well as information on other non-commercial models.
Notes about the plot
MMLU, while somewhat outdated, remains a widely reported AI benchmark that facilitates comparisons across models. It was chosen for this analysis due to the ready availability of performance numbers.
The x-axis is the MMLU accuracy (%). The y-axis is the log scale of cost per million tokens, calculated as the average of both input and output price. Different colors indicate different years.
For models like Gemini Pro, PaLM and PaLM 2, the character-based pricing was multiplied by 4 to roughly estimate equivalent token-based pricing for fair comparison.
Some models (Gemma 7B, Grok-1, Grok-1.5, Gemini Ultra, GPT-4.5) are represented by dashed lines, indicating either lack of publicly available pricing information or unreported 5-shot-type MMLU scores. This incompleteness limits direct comparisons but their inclusion still provides useful context.
GPT-4 offers two price points based on context window size (8K vs 32K tokens), while Claude 3 models maintain consistent pricing regardless of context window.
I tried to take relatively fair numbers for MMLU scores (e.g. 5-shot CoT, 5-shot)
Price-performance Pareto frontier
The Pareto frontier in this context would refer to the set of models that are considered optimally efficient, meaning they offer the best trade-off between MMLU accuracy (on the x-axis) and cost per million tokens (on the y-axis). However, identifying the most optimal models depends on the specific needs and preferences of the user, particularly their sensitivity to price and performance. To better understand this, I’ll consider three archetypes of customers:
1. Price-sensitive customers
Price-sensitive customers are those who prioritize cost over all other factors. An example may be a small startup with limited funding that prioritize cost above all to extend their runway or independent developers working on a budget who are willing to spend a bit more for added performance to ensure their app has a competitive edge.
They seek the most affordable options that still meet a minimum threshold of performance. On the chart, these customers would likely focus on models clustered towards the lower end of the y-axis, which represents lower costs per million tokens. Even if these models have lower MMLU accuracy, the primary concern for very price sensitive customers is to minimize expenses while still achieving an acceptable level of performance.
Here the Pareto frontier model is actually Claude 3 Haiku, being the most affordable and have the highest reasoning accuracy of 75.2% in that class.
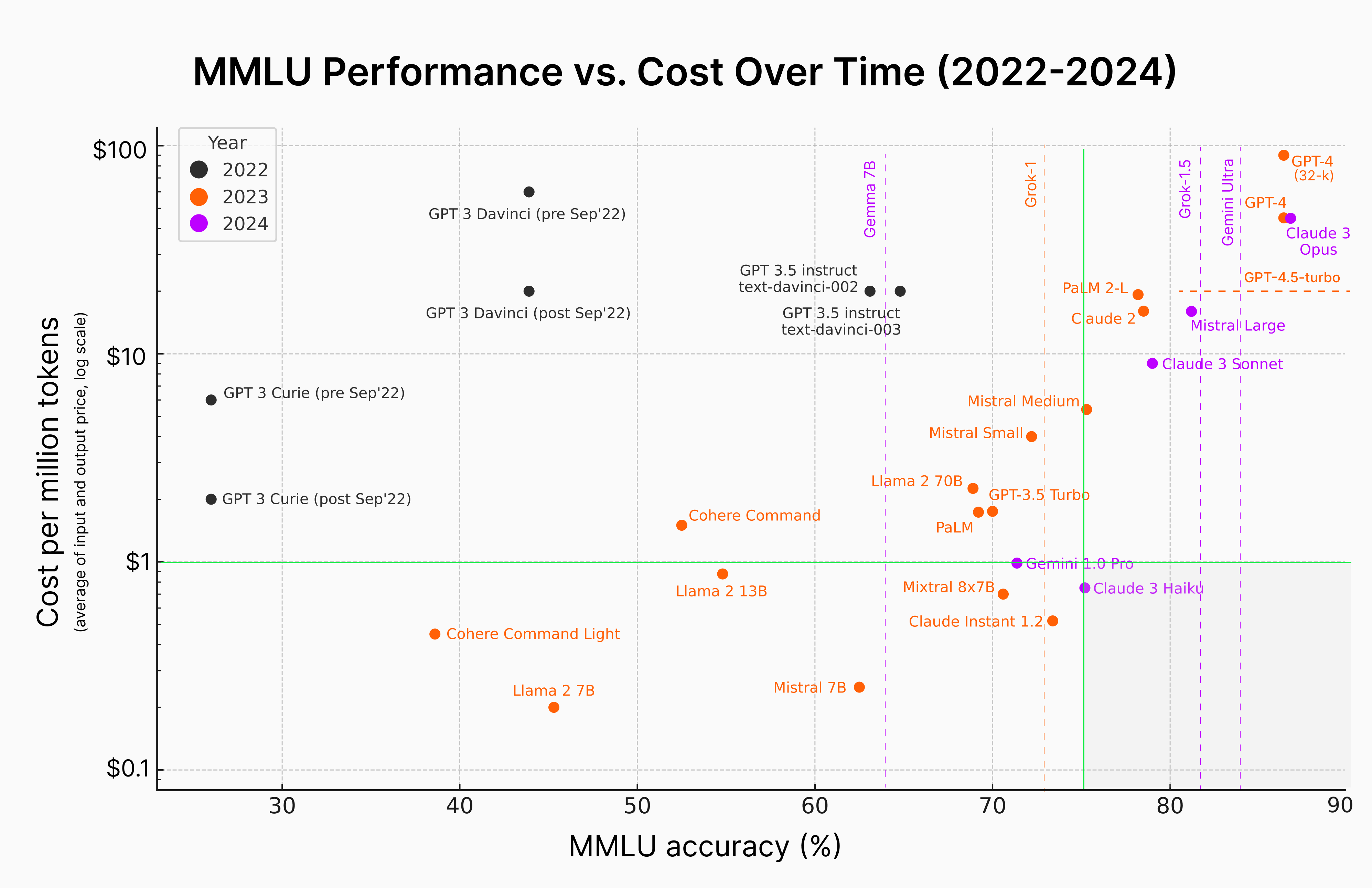
Obviously, a customer can choose what level of performance is acceptable for their specific use case. For instance, if they are comfortable with models that achieve an MMLU accuracy of 70% or higher, then the most optimal models, in order of cost-efficiency, would be Claude Instant 1.2, Mistral 8x7B, Claude 3 Haiku , Gemini 1.0 Pro

If a customer is primarily price-sensitive and does not have strict performance requirements, then the most cost-effective options would be Llama 2 7B and Mistral 7B.
2. Balanced customers
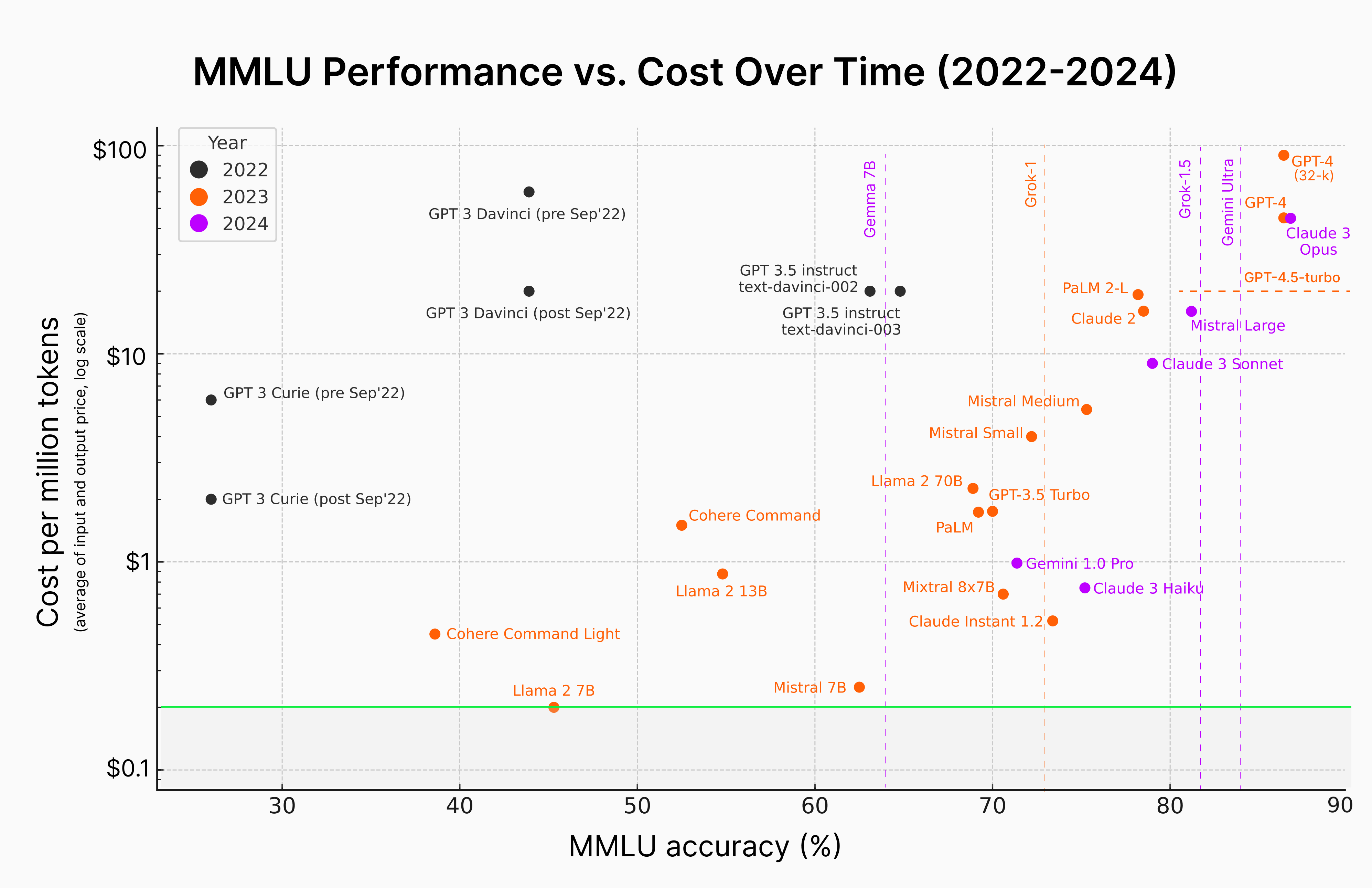
Moderately price-sensitive customers aim for a balance between cost and performance. A B2B tech company experiencing growth might prioritize performance to support scaling but still needs to be mindful of costs. They would seek high-performing models on the Pareto frontier but stop short of the most expensive options.
They are willing to pay slightly more for improved accuracy but still want to avoid the top-end pricing. On the chart, these customers would be looking at the models that lie somewhat in the middle of the Pareto frontier, representing a middle ground in the trade-off between cost and MMLU accuracy.

The most optimal model in this class is Claude 3 Sonnet being a bit under $1 per 1M token while almost achieving 79% on MMLU. Grok-1.5 (81.3%) might also be the most optimal model, though the pricing is not clear.
3. Performance-driven customers
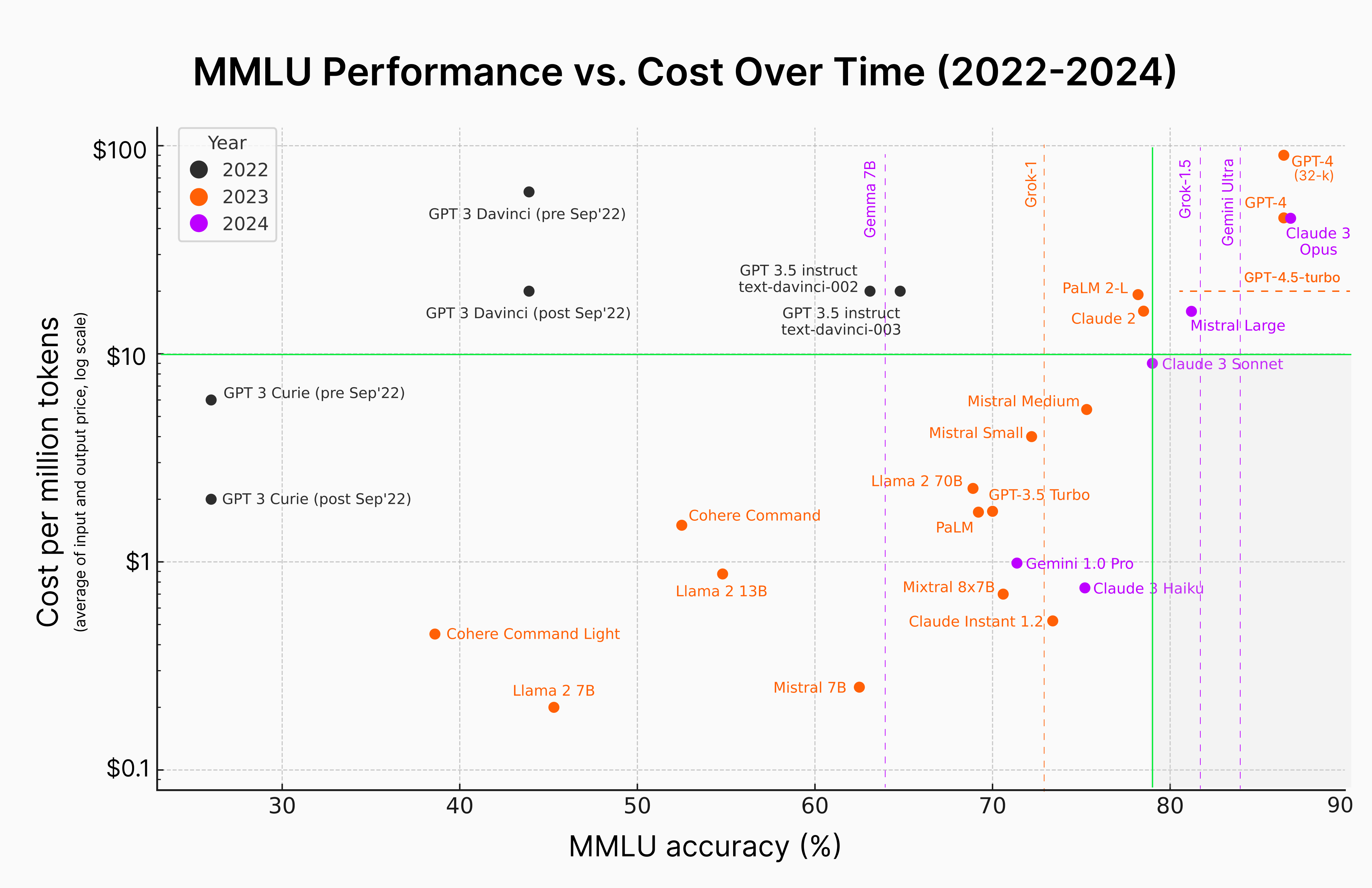
Performance-oriented customers are less concerned with cost and place a higher value on the performance and capabilities of the models. Large enterprises that rely on AI for critical applications, like financial forecasting or medical diagnostics, might prioritize performance above all. They would likely consider models at the high end of the Pareto frontier, where the costs are justified by the returns on investment from high accuracy.
On the chart, these customers would focus on the models that are farthest to the right, as these offer the highest accuracy, even if the cost per million tokens is higher.

The future
From 2022 to 2024 there is a clear trend of models achieving higher MMLU accuracy scores while simultaneously becoming more affordable. If this trend continues, we may see incremental progress along the current trajectory, potentially within less than a year. Basically, we may see models surpassing the 80% MMLU accuracy threshold at costs below $1 per million tokens.

I predict that within the next 1-1.5 years from now, we will see language models achieving >=90% or higher accuracy on the MMLU benchmark in both 5-shot and 0-shot settings, while incrementally reducing costs. This will allow for greater adoption with lower pricing.

Looking at the 2-5 year projection, models might push further into the upper right quadrant of the chart with MMLU accuracy could approach 95-100% at a fraction of today's prices, shifting the Pareto frontier of optimal price-performance trade-offs and making powerful AI reasoning more accessible.

Concluding thoughts
As capabilities improve, we may see a cost stratification, with premium models catering to high-end applications and more affordable options for mainstream use cases.The Pareto frontier of optimal price-performance trade-offs will likely shift as models become more capable, cost-effective to train and serve at inference time.
In my opinion, this also means at least three other things:
Accelerated research velocity with more affordable models. New interesting research directions will involve hardware optimization, efficient RL training, optimal synthetic data mixtures, and much more.
Greater model differentiation. As the AI market matures, we can expect to see a wider range of specialized models tailored for specific industries, domains, and use cases, offering unique capabilities and performance characteristics
Potential for new benchmarks. The emergence of more diverse and capable AI models may necessitate the development of novel benchmarks and evaluation metrics to accurately assess their performance, generalization abilities, and suitability for various applications. For example, I would be excited to see model makers start adopting GPQA instead of MMLU in the near future.
But obviously the nature of AI capabilities will change over time too. While reasoning performance on benchmarks like MMLU may be a key focus today, it might not hold the same significance in five years. Instead, the emphasis may shift towards specific capability-cost trade-offs that align with the needs and priorities of the AI landscape at that time.
This idea came from our conversation with Jason Wei as we were vacationing in the historical osteria (highly recommend!) near the Pantheon in Rome, Italy.
Post DeepSeek this article seems very prescient!
Great write up Karina! Love the graphic you created, I think it does such a good job of encapsulating the trend we’re seeing with model performance vs cost. Also loved your mention of developing improved benchmarks for the future - lots to think about.